Deploy Spark Standalone Cluster and Connect to Jupyter Lab Locally
Background

Apache Spark is one of the most widely used frameworks for distributing data in parallel across a cluster, and it often works together with Hadoop in Big Data analytics. A standard Spark cluster architecture as below:

The application will be submitted to a Spark driver, from there it connects to a Spark cluster. The driver will separate the application into small tasks, then send them to the worker nodes, so the driver program must be network addressable. An executor will be created inside of each node to handle task processing. The cluster manager, also called Spark master, allocates resources to the worker nodes. Depending to your goal, Apache Spark provides four different cluster managers for you to choose from: standalone, Hadoop YARN, Mesos, Kubernetes.
To have a quick start of Spark, standalone cluster has a fairly complete set of capabilities and rather simpler setup comparing to other cluster managers. We will demo how to deploy a Python application from Jupyter Notebook to a standalone Spark cluster on the localhost through Docker containers.
Requirements
We are using Spark 3.0 and Python 3.8
Spark Cluster Setup
In this demo, we will create a Linux EC2 instance on AWS (Free tier of course!) as a remote standalone spark cluster. This cluster will have one master and one worker (you could feel free to add more workers) and their are running in docker containers
To deploy this cluster, we use this docker compose file from here, as below:
version: '3'
services:
spark-master:
image: bde2020/spark-master:3.0.1-hadoop3.2
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:3.0.1-hadoop3.2
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
environment:
- "SPARK_MASTER=spark://spark-master:7077"Run docker-compose up command and then we should be able to monitor the cluster at http://<ec2-public-ip>:8080.

Jupyer Lab Setup
We use this image developed by the Jupyter community to create our Jupter Lab container. Ensure you have docker installed in your working environment. In Terminal run this command:
$ docker run -d -p 8888:8888 -p 4040:4040 -e JUPYTER_ENABLE_LAB=yes --name notebook jupyter/all-spark-notebookCheck the docker log to get the token for log in to Jupyter Lab UI:
docker logs --tail 3 notebookIn this case, we got this:

Copy the last link to your browser, it would connect you to the Jupyer Lab UI
Submit Application to Standalone Cluster
To connect spark cluster, we need to config the application in order to locate the cluster master.
import pyspark
sc = pyspark.SparkContext(master='<spark_master_url>',
appName='<app_name>')Replace the <spark_master_url> with spark://<ec2-public-ip>:7077 and give a name for your application.
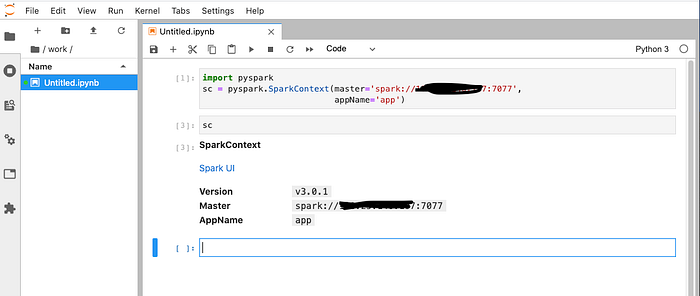
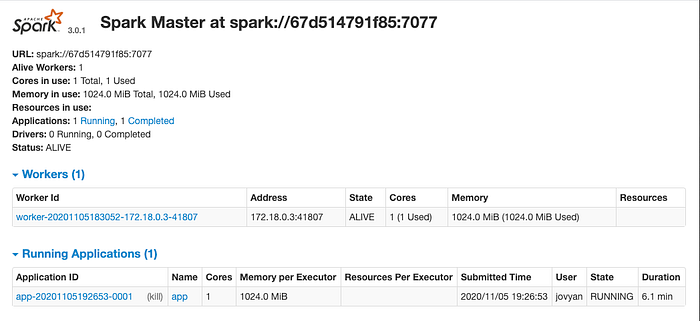
Back to master UI, you should be able to see your application have been submitted:
Discussion
In this approach the Driver Program locates inside the application container, this is so called client mode. In the client mode, the driver launch within the application. Spark also has another deploy mode called cluster mode, the driver might be running as one of the worker node. If the application is far from the worker nodes, it is better to use cluster mode to reduce network latency. However, as of Spark 3.0.1, standalone cluster only supports client mode for Python application, we could bypass this by configuring the SparkSession or using Hadoop’s YARN as the Cluster Manager but the Jupyter Lab has to be enabled the Enterprise Gateway feature.
Standalone is not a common choice for production but if you just want to get your hands dirty and learning about Spark, standalone is always an easy one to begin with.
I have not tested on other version of Spark or python, but I would guess the code should work on any spark version after 2.4.
